


Introduction
TL/DR if want to see a working example of Terraform, CI/CD, Azure DevOps, and YAML templates check out my GitHub Repo TheYAMLPipelineOne
A constant ask at any customer when dealing with Terraform is: “How do we configure this for our CI/CD Pipelines?”. The honest answer to this is…..IT DEPENDS! Just like with many areas withing IT there is no one size fits all solution.
This post will deal with one approach leveraging Terraform, CI/CD, Azure DevOps, and YAML Templates. For starters if you are unfamiliar with YAML Pipelines and specifically my approach to them check out the following blog posts:
- YAML Deployment Pipelines (YoutTube)
- Advanced Azure DevOps YAML Objects
- Leveraging YAML Pipelines: The New Deployment Architecture
- Multi-Stage YAML Pipelines in a Microservice Architecture. Making Life Easier
Specifically we will be leveraging the Azure Pipelines Terraform Tasks marketplace extension. I prefer this one as it handles a lot of functionality, such as passing variables and running an apply only when changes are detected. This in addition to a nice User Interface when viewing plan details. Can read on my experience leveraging this task here.
Philosophy
Template Structure
To be successful in this approach it helps to understand the why the templates are structured the way they are and what their design is. First and foremost I am a huge advocate for the Don’t Repeat Yourself (DRY) methodology when it comes to YAML Templates.
For this to be successful it all starts with the task. A Task must be configured in such a way the majority of it’s inputs are parameterized. Now wait….are we going to ask and require every input? No. This is where defaulting to the 80% rule comes into play. We can default it to the value we are most likely wanting to use.
Here is an example of what I am referring to:
parameters:
- name: terraformVersion
type: string
default: 'latest'
steps:
- task: TerraformInstaller@0
displayName: install terraform
inputs:
terraformVersion: ${{ parameters.terraformVersion }}
Rather then set the terraformVersion to always use latest we are parameterizing it. This provides the ability for anything calling this task to pass in it’s own value…..or assume the default!
This philosophy trickles up when we start talking about creating a “build” and an “apply” task.
Terraform Build
I define a Terraform Build one that accomplishes the following:
- Publish Terraform files as an Artifact
- Install Terraform
- Run Terraform
init - Run a
planfor ALL desired environments
Now these steps, minus the publishing artifact, should be all repeatable and encapsulated so a job can run this in parallel. This is important concept as if we define the task once and the task series once we can re run it for multiple environments simultaneously since there aren’t any dependencies.
I also want to call out that these tasks can create a stage which we reuse for our PR builds. There really is no difference between these activities.
Terraform Apply
For me Terraform Apply steps would be defined as:
- Install Terraform
- Run Terraform
init - Run Terraform
plan - Run Terraform
apply
These steps significantly overlap with the Terraform Build process. This means that we should be leveraging the same tasks that were defined in that process…we just add an additional one for the apply.
Now, you might be calling out why are we running a plan again? This could be done for a couple different reasions:
- Validate what the plan was going to execute since the Azure Resource could have changed from the Build
- Insert a stop for an approval of the change before the environment.
- Providing the plan for any type of Change Management Documentation
Environments/Variables
This is a tricky one. For this to work we have named the Azure DevOps Environment, YAML Variable template file, Terraform *.vars file, ADO Stage and Job Names all reference this. By having this alignment on a naming standard it makes life much much easier.
Since our dev, tst, and prd, ADO environments are passed in as Azure DevOps parameters we can leverage that name to also reference our ADO variables YAML template and pass it in to the Terraform commands requiring a *.vars path. (Full disclosure I have also done this by using an environment directory approach. It just requires updating the additionalParameters and setting up the TerraformDirectory in the variables.yml file)
Here is an example of a Dev ADO variables.yml file:
variables:
AzureSubscriptionServiceConnectionName: Example - Dev
TerraformDirectory: Infrastructure
TerraformStateStorageAccountContainerName: terraform-state
TerraformStateStorageAccountName: sastorageaccount
TerraformStateStorageAccountResourceGroupName: rg-terraformexample-dev-eus
Can see all the necessary connection information can be dynamically stored in a variable file. Alternatively if using secrets as opposed to Service Principles to access the Terraform backend state can store those in an ADO Variable Group and reference those variables as opposed to a template file. The only additional step is authorizing the pipeline to access the ADO Variable Group.
Repository
I have the terraform_build_stage.yml and terraform_apply_stage.yml out in my TheYAMLPipelineOne repository. One should be able to quickly get up to speed by configuring the variable file to match what is needed in their environments.
Odds are this will require updating the Terraform directory to match their solution(s). Which also consistency is key. These templates will work best if solutions follow a specific naming pattern.
Additionally the serviceName parameter will need to be updated. This is mainly used for job display information; however, in my advanced deployments that deploy Infrastructure as Code (IaC) and app code this could be more important as it could match the actual app service name.
End Result
We can have multiple repositories with Terraform execute the exact same steps with a minimal amount of code. For example:
parameters:
- name: environmentObjects
type: object
default:
- environmentName: 'dev'
regionAbrvs: ['eus']
- environmentName: 'tst'
regionAbrvs: ['eus']
- name: templateFileName
type: string
default: 'main'
- name: templateDirectory
type: string
default: 'Infrastructure'
- name: serviceName
type: string
default: 'storageAccountA'
stages:
- template: stages/terraform_build_stage.yml@templates
parameters:
environmentObjects: ${{ parameters.environmentObjects }}
templateFileName: ${{ parameters.templateFileName }}
serviceName: ${{ parameters.serviceName }}
- ${{ if eq(variables['Build.SourceBranch'], 'refs/heads/main')}}:
- template: stages/terraform_apply_stage.yml@templates
parameters:
environmentObjects: ${{ parameters.environmentObjects }}
templateFileName: ${{ parameters.templateFileName }}
serviceName: ${{ parameters.serviceName }}This Pipeline would be triggered first as a branch policy on main. This would then ensure the Terraform Build stage will execute. Once merged it will then run another Terraform Build and subsequent Terraform Apply across ALL the environments/regions.

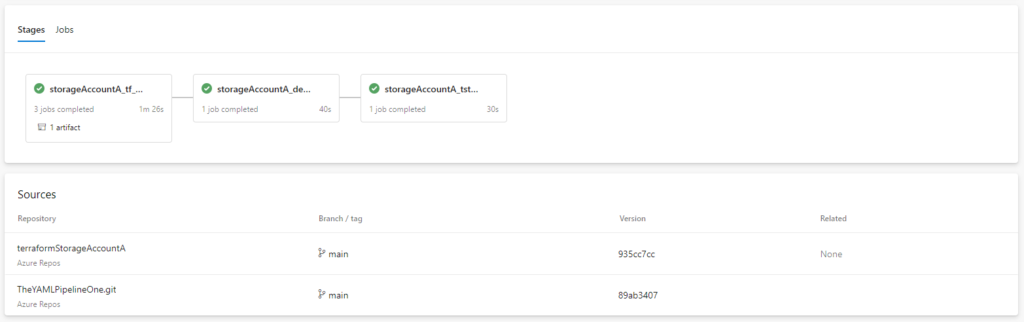
And why not show that this works for another repo:

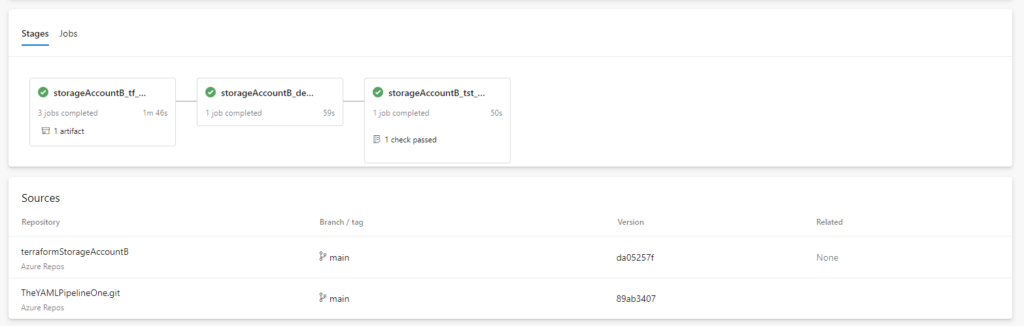
Conclusion
There are many solutions to CI/CD for Terraform pipelines. This is just an example of Terraform, CI/CD, Azure DevOps, and YAML Templates. Hopefully this was helpful. All code samples and working templates can be found in TheYAMLPipelineOne GitHub repo.